
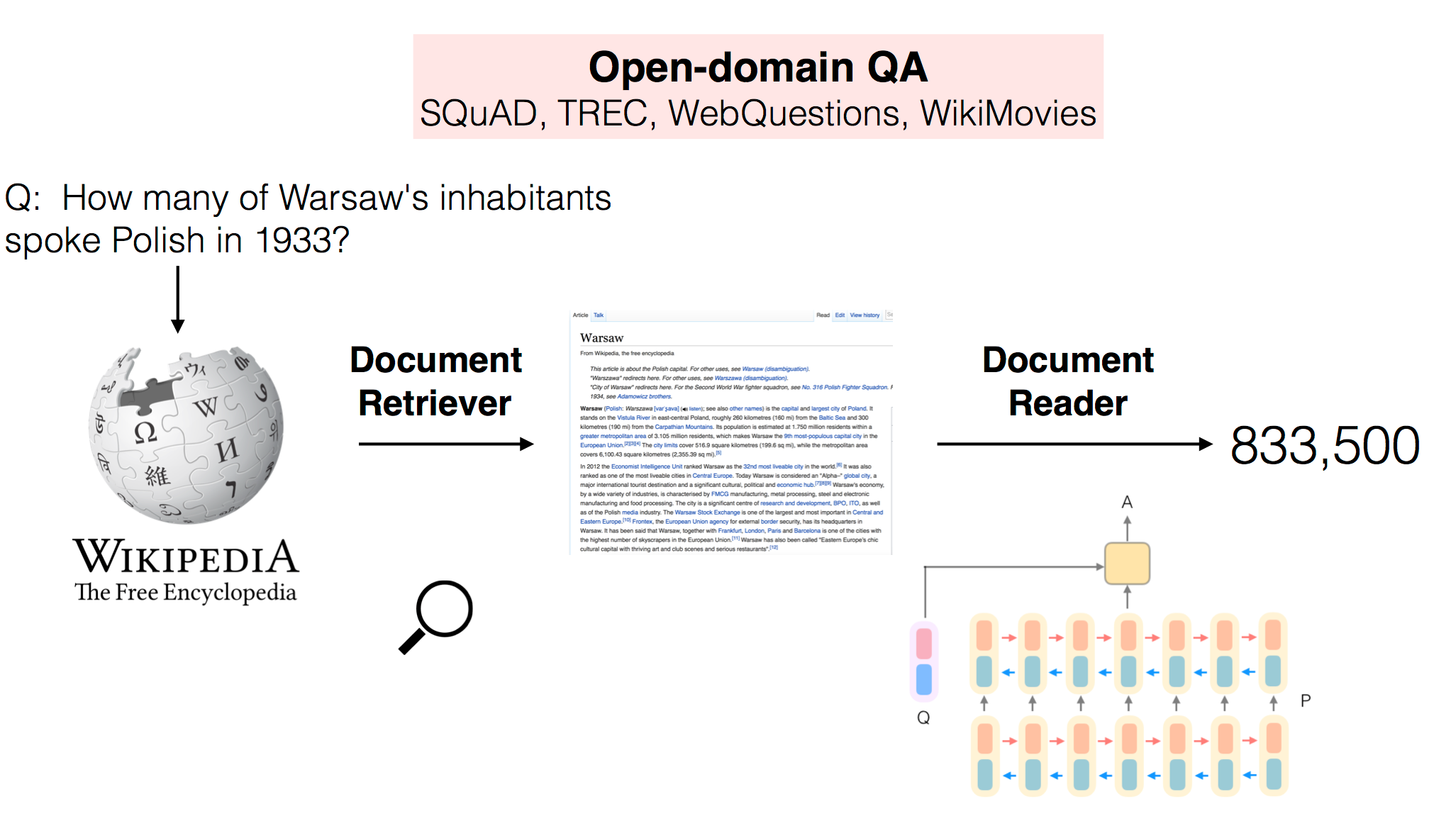
DrQA 是一个基于维基百科数据的开放域问答系统,它由检索器和阅读器组成。其中检索器用于从海量的文本(例如维基百科)中获得相关的文章;阅读器用于从文章中获得相应的答案。
官方介绍:
DrQA是一个应用于开放域问答的阅读理解系统。特别是,DrQA的目标是“大规模机读”(MRS)。在这个设定中,我们在可能非常大的非结构化文档集中搜索问题的答案。因此,系统必须将文档检索(查找相关文档)的挑战与机器对文本的理解(从这些文档中识别答案)的挑战相结合。
我们使用DrQA的实验侧重于回答factoid问题,同时使用Wikipedia作为文档的独特知识源。维基百科是一个非常适合大规模,丰富,详细信息的来源。为了回答任何问题,必须首先在超过500万个文章中检索可能相关的文章,然后仔细扫描它们以确定答案。
请注意,DrQA将Wikipedia视为一个通用的文章集合,并不依赖于其内部知识结构。因此,DrQA可以直接应用于任何文档集合。
数据集:维基百科
框架:PyTorch
版本:PyTorch torch-0.3.0
论文:Reading Wikipedia to Answer Open-Domain Questions
项目:https://github.com/facebookresearch/DrQA
系统架构:
实战:
交互模式下提问:
where is stanford university
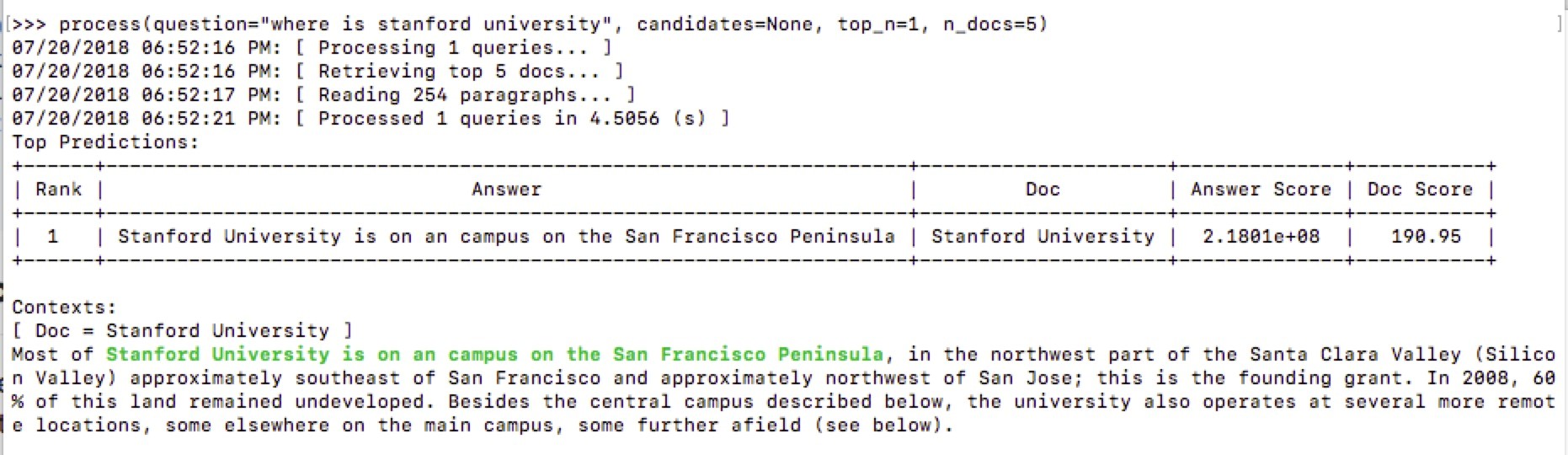
可以看到检索到的文档是 Stanford University,问题的答案是:浅绿色标注的部分,答案非常的精准。
交互模式下提问:
where is Barack Hussein Obama from
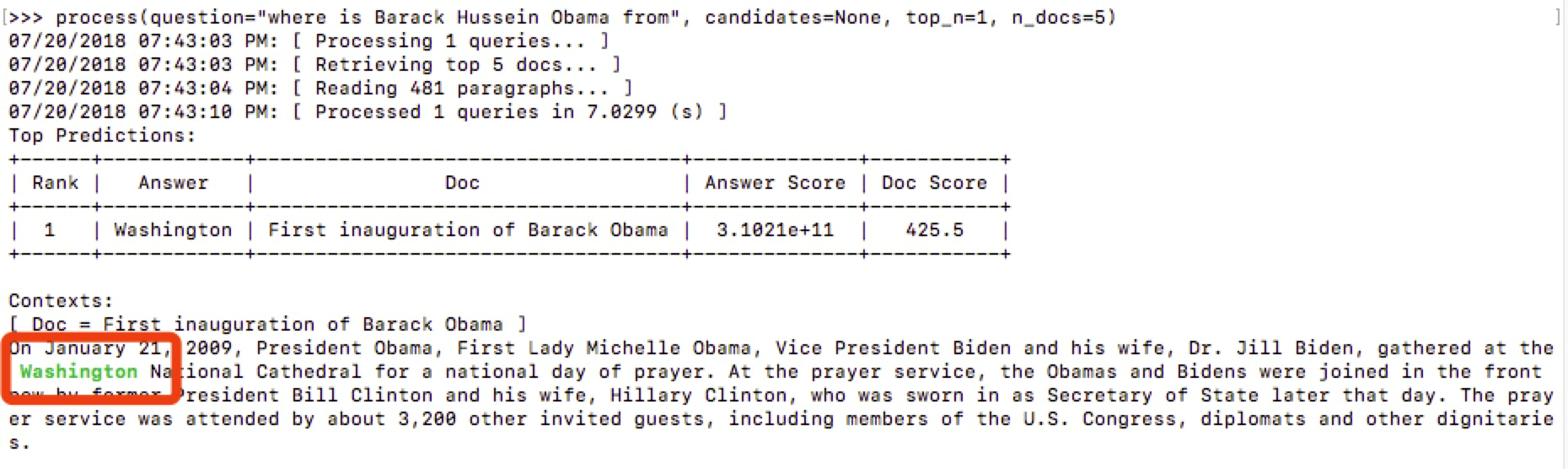
回答不是很精准,我其实想问的是奥巴马来自哪里。答案返回的是奥巴马在哪里,奥巴马在华盛顿,不过也还是相当不错。
who is Donald Trump
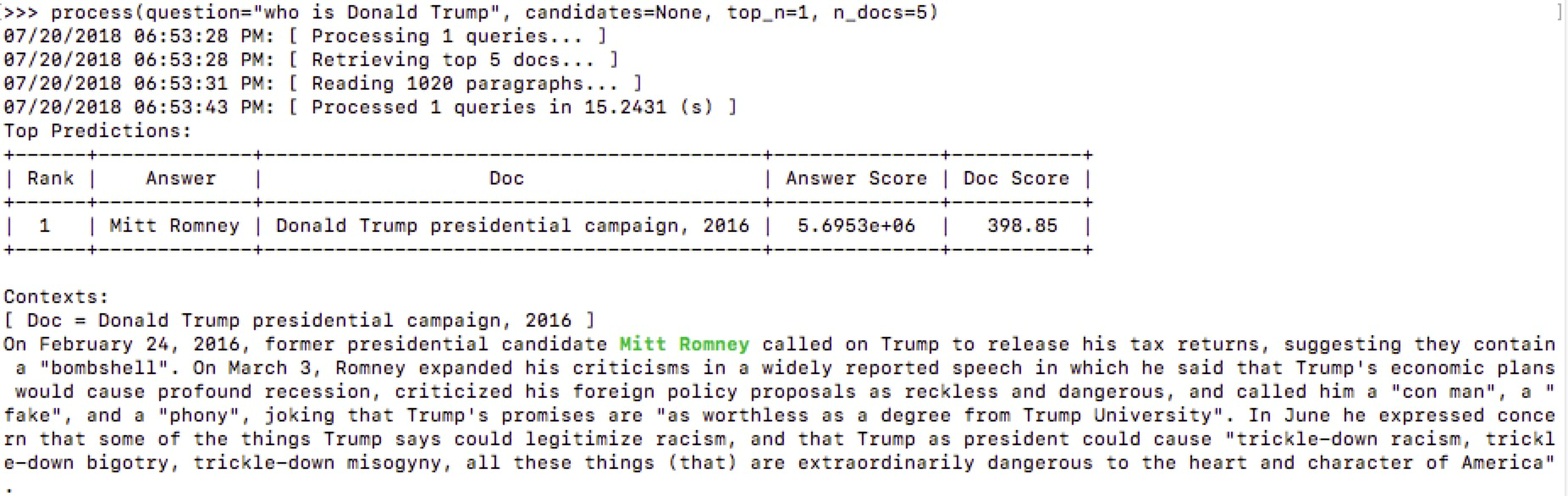
这个问题并没有找到准确的答案,虽然文档是相关的。

