发布人:Google 研究科学家 Chris Olston 和 TensorFlow Serving 软件工程师 Noah Fiedel
自从在 2016 年 2 月首次开源 TensorFlow Serving 以来,我们已经进行了一些主要增强。我们来看一下最初的工作、回顾我们的进展并与大家分享一下未来的发展方向。
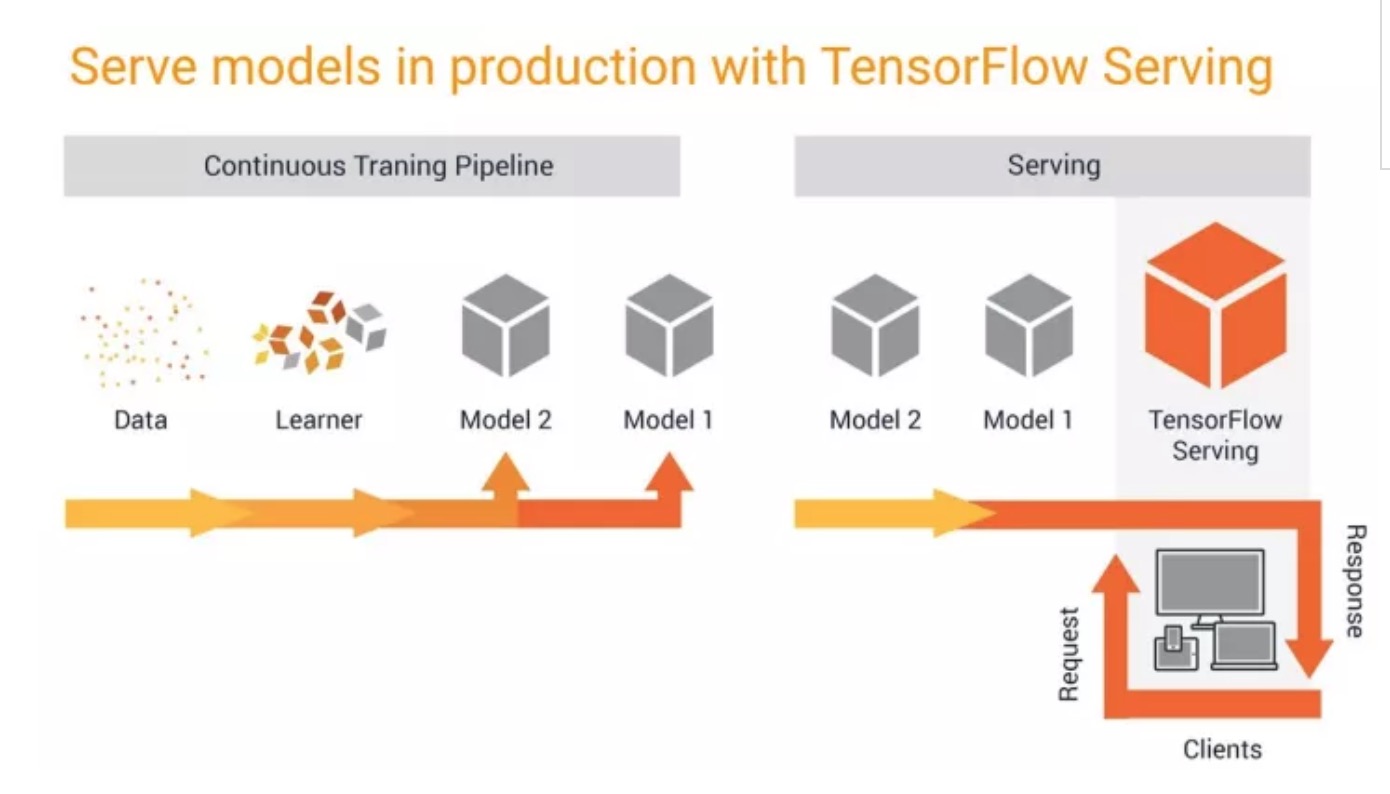
在 TensorFlow Serving 推出之前,Google 内部的 TensorFlow 用户必须从头自行创建服务系统。虽然服务一开始看起来非常轻松,但是一次性服务解决方案的复杂性快速提升。机器学习 (ML) 服务系统不仅需要支持模型版本化(对于带回滚选项的模型更新)和多种模型(通过 A/B 测试进行的实验),而且还得确保并行模型在硬件加速器(GPU 和 TPU)上实现高吞吐量和低延迟时间。因此,我们着手创建一个独立、通用的 TensorFlow Serving 软件堆栈。
我们从一开始就决定将它开源,开发工作于 2015 年 9 月启动。我们在短短几个月内创建了最初的端到端工作系统,并于 2016 年 2 月发布开源版本。
过去一年半以来,在公司内外的用户和合作伙伴的帮助下,TensorFlow Serving 在性能、最佳做法和标准方面有了长足的进步:
开箱即用的优化服务和可定制性:我们现在提供一个预构建的规范服务二进制文件,这个文件针对带 AVX 的现代 CPU 进行了优化,因此,开发者无需从我们的库自行汇编二进制文件,除非他们有特殊需求。同时,我们还添加了一个基于注册表的框架,让我们的库可以用于自定义(甚至是非 TensorFlow)服务情景。
多模型服务:从一个模型扩展到多个并行服务模型会出现一些性能障碍。我们通过以下方式平稳地服务多个模型:(1) 在隔离的线程池中加载,以免导致需要流量的其他模型的延迟时间飙升;(2) 在服务器启动时并行加速所有模型的初始加载;(3) 利用多模型批次交错复用硬件加速器 (GPU/TPU)。
标准化模型格式:我们向 TensorFlow 1.0 中添加了 SavedModel,从而为社区提供了一种可以跨训练和服务工作的单一标准模型格式。
易于使用的推理 API:我们为常见的推理任务(分类、回归)发布了易于使用的 API,这些 API 适合我们广泛的应用。为了支持更高级的用例,我们推出了一个低级别基于张量的 API(预测)和一个支持多任务建模的全新多重推理 API。
我们的所有工作都是通过与以下各方的密切合作实现的:(a) Google 的机器学习 SRE 团队,他们帮助确保了我们团队的稳健发展并满足内部服务等级协议 (SLA) 要求;(b) 其他 Google 机器学习基础架构团队(包括广告投放和 TFX);(c) 应用团队,例如 Google Play;(d) 我们在加州大学伯克利分校 RISE 实验室的合作伙伴,他们探索了与 Clipper 服务系统互补的研究问题;(e) 我们的开源用户群和贡献者。
目前,TensorFlow Serving 每秒为 1100 多个自有项目(包括 Google 的云机器学习预测)处理着数以千万计的推理。我们的核心服务代码通过开源版本向所有人提供。
展望未来,我们的工作远未完成,我们将继续探索众多创新途径。今天,我们非常高兴地与大家分享我们在两个实验性领域的早期进展:
精细批处理:我们在专用硬件(GPU 和 TPU)上实现高吞吐量的一种关键技术是“批处理”,即同时处理多个示例以提高效率。我们正在开发技术和最佳做法来改进批处理,以便实现以下两个目标:(a) 让批处理仅针对计算的 GPU/TPU 部分,最大程度提高效率;(b) 在递归神经网络内实现批处理,用于处理序列数据,例如文本和事件序列。我们正在利用 Batch/Unbatch 运算对开展任意子图表的批处理实验。
分布式模型服务:我们正在研究将模型分片技术作为处理模型的一种方法,这些模型由于太大而无法适应一个服务器节点,或者不能以节省内存的方式共享子模型。我们最近在生产中推出了一个超过 1TB 的模型,并取得了良好的效果,希望可以很快将这个功能开源。
再次感谢提供反馈、代码和想法的所有用户和合作伙伴。欢迎大家加入项目,链接为 github.com/tensorflow/serving
原文链接:http://mp.weixin.qq.com/s/CC5-iT6OmrA3-rdEvvdq1g

