SRU is a recurrent unit that can run over 10 times faster than cuDNN LSTM, without loss of accuracy tested on many tasks.
SRU 是一个循环单元可以运行 10 倍速度相比 cuDNN LSTM,在很多的任务上没有失去准确率。
论文地址:https://arxiv.org/abs/1709.02755
项目地址:https://github.com/taolei87/sru
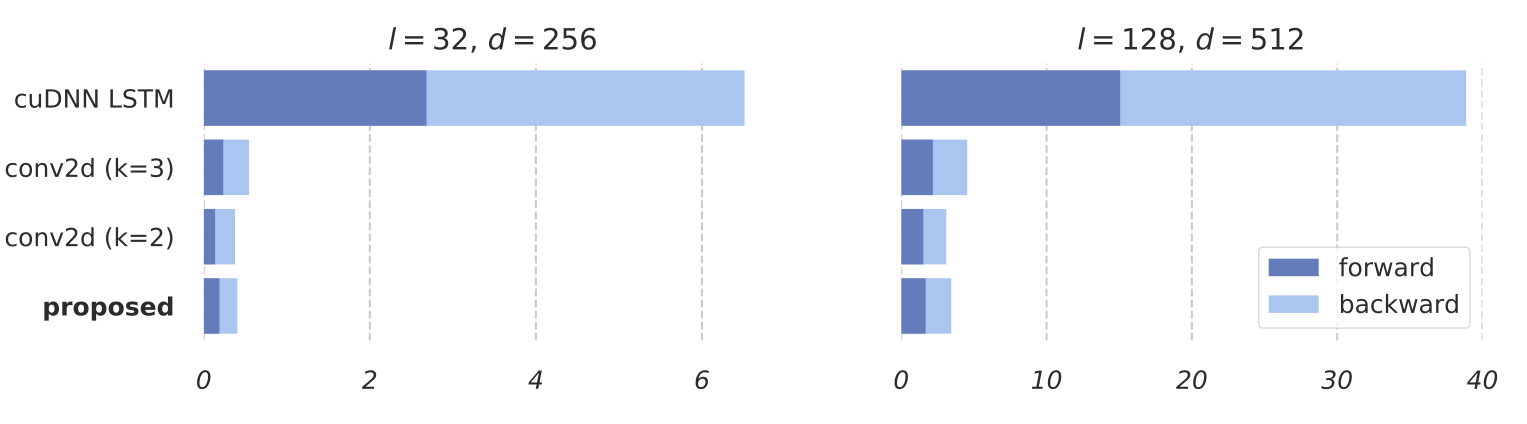
Average processing time of LSTM, conv2d and SRU, tested on GTX 1070
For example, the figure above presents the processing time of a single mini-batch of 32 samples. SRU achieves 10 to 16 times speed-up compared to LSTM, and operates as fast as (or faster than) word-level convolution using conv2d.