
Ray
介绍
GRU(Gated Recurrent Unit) 是由 Cho, et al. (2014) 提出,是LSTM的一种变体。GRU的结构与LSTM很相似,LSTM有三个门,而GRU只有两个门且没有细胞状态,简化了LSTM的结构。而且在许多情况下,GRU与LSTM有同样出色的结果。GRU有更少的参数,因此相对容易训练且过拟合问题要轻一点。
目录
- GRU原理讲解
- Keras实现GRU
一、GRU原理讲解
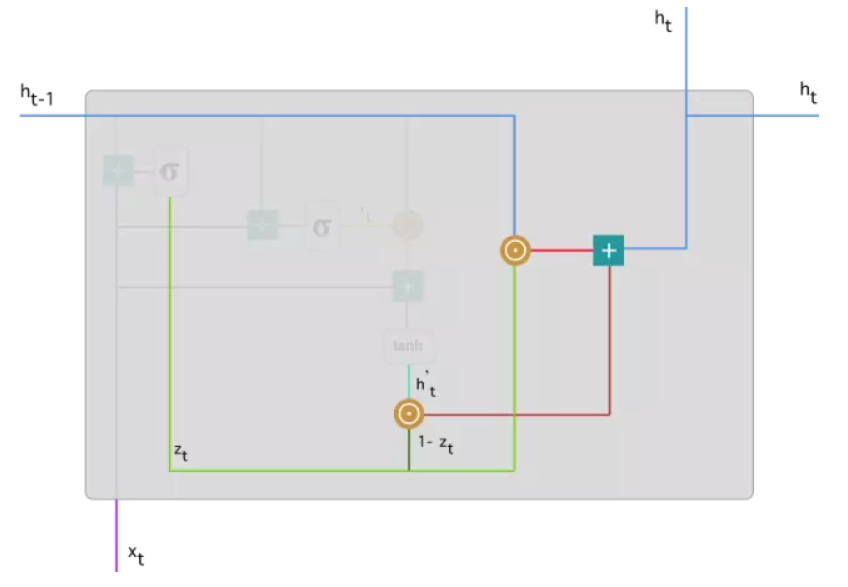
下图展示了GRU的网络结构,GRU的网络结构和LSTM的网络结构很相似,LSTM中含有三个门结构和细胞状态,而GRU只有两个门结构:更新门和重置门,分别为图中的z_t和r_t,结构上比LSTM简单。
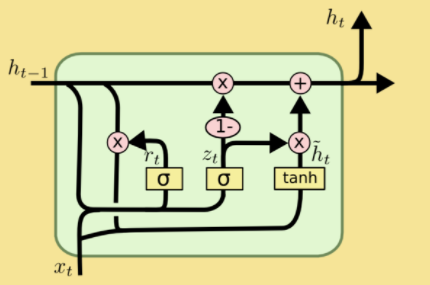
将GRU网络结构具体运算操作用下图进行表示。接下来将会针对该图每一部分进行详细的讲解。
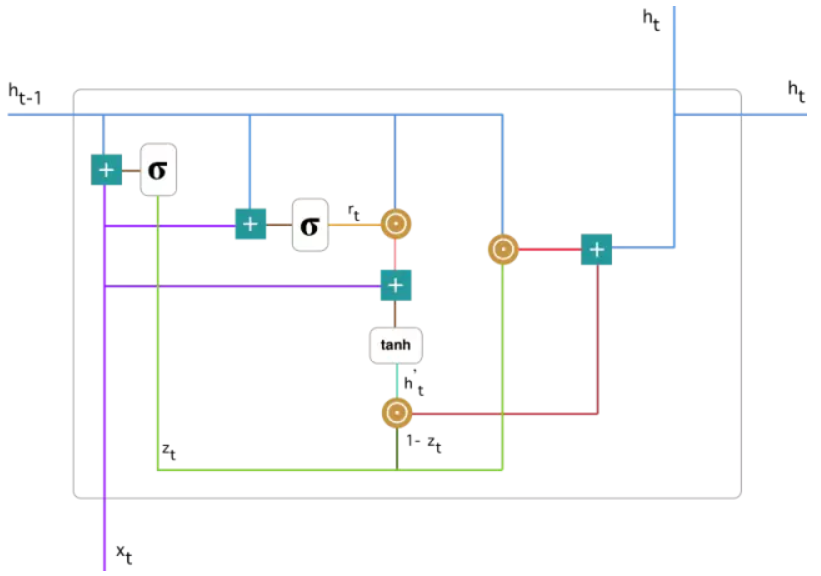
首先说明图中每个符号的意义:

1.更新门(update gate):
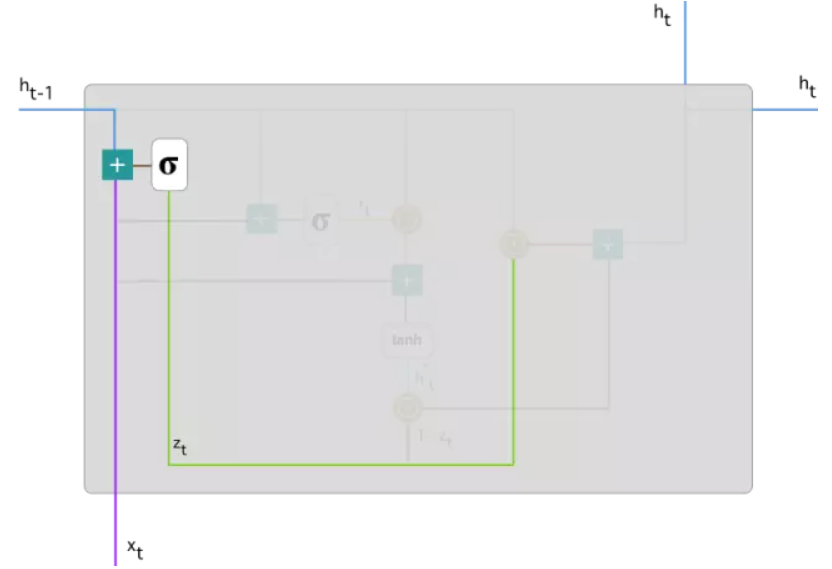
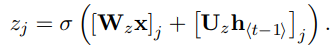
[.]j表示一个向量的第j个元素。与LSTM中忘记门和输入门的操作一样,也是该时刻的输入x_t、上一时刻隐藏层h(t-1)分别和权重矩阵W_z、U_z相乘,再将这两部分结果相加后放入sigmoid激活函数中,将结果压缩在0-1之间。
更新门的作用是决定上一层隐藏层状态中有多少信息传递到当前隐藏状态h_t中,或者说前一时刻和当前时刻的信息有多少需要继续传递的(在最后的公式中可以看到此功能的表示,并有详细讲解更新门为什么有这个作用)。当z_j越接近0为说明上一层隐藏状态的第j个信息在该隐藏层被遗忘,接近1则说明在该隐藏层继续保留。
2.重置门(reset gate):
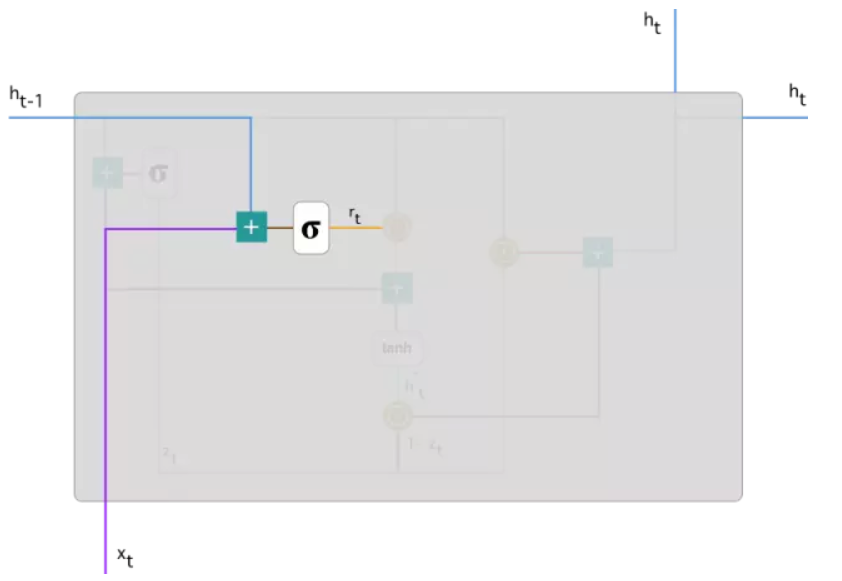
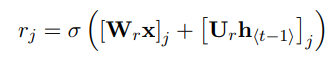
和更新门的运算操作类似,只是权重矩阵不同而已。重置门是决定上一时刻隐藏状态的信息中有多少是需要被遗忘的。当该值接近于0,则说明上一时刻第j个信息在当前记忆内容(在后文解释该词)中被遗忘,接近于1则说明在当前记忆内容中继续保留。
读到这里,有些读者可能会感觉重置门和更新门的作用很相似,是否可以再简化只用一个门即可?其实不然,这两个门作用的对象是不一样的,GRU虽然没有LSTM的细胞状态,但是它有一个记忆内容,更新门是作用于上一时刻隐藏状态和记忆内容,并最终作用于当前时刻的隐藏状态(如文中最后一条公式所表达),而重置门作用于当前记忆内容。
3.确定当前记忆内容: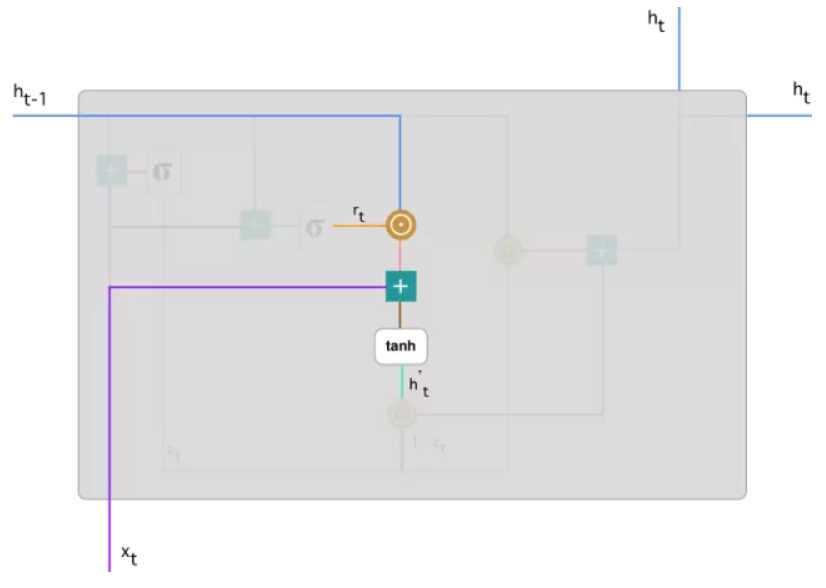
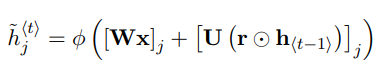
除了和上面两个门一样与权重矩阵相乘之外,还计算重置门结果r_t和h_(t-1)进行Hadamard乘积,即对应元素相乘。因为r_t是由0到1的向量组成的,因此,进行Hadamard乘积的意义就在于使用重置门决定在当前记忆内容中要遗忘多少上一时刻隐藏状态的内容,正如重置门处描述,值接近于0说明该信息被遗忘,接近于1则保留该信息。最后再将这两部分信息相加放入tanh激活函数中,将结果缩放到-1到1中。
记忆内容就是GRU记录到的所有重要信息,类似于LSTM中的细胞状态,比如在语言模型中,可能保存了主语单复数,主语的性别,当前时态等所有记录的重要信息。
因此,通过此处的运算操作的说明,就可以了解该时刻的记忆内容由两部分组成,一部分是使用重置门储存过去相关的重要信息,另一部分是加上当前时刻输入的重要信息。这两部分就组成了当前时刻的所有记忆内容。
4.确定当前时刻隐藏层保留的信息:
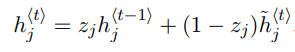
(公式说明:此处是标量相乘,若是以向量表示,需要使用Hadamard乘积)
解释在第2部分更新门处遗留的问题:
最后,该网络需要计算 h_t向量,该向量将保留当前单元的信息并传递到下一个单元中。在此过程,使用更新门,一方面,如公式第一项,它决定了上一个时刻的h_(t-1)中多少信息在此时刻隐藏单元h_t需要保留,另一方面,如公式的第二项,通过(1-z_j)表示那些需要遗忘的信息,用此时刻的记忆内容中相应的内容进行更新。这样更新门就能决定了分别需要在当前时刻的记忆内容和上一时刻隐藏层的信息收集哪些内容了。
需要注意的是,虽然隐藏层信息的符号和当前记忆内容的符号相似,但是这两者是有一定的区别的。当前记忆内容在上文中已经说明了是当前时刻保存的所有信息,而隐藏层信息则是当前时刻所需要的信息。比如在语言模型中,在当前时刻可能我们只需要知道当前时态和主语单复数就可以确定当前动词使用什么时态,而不需要其他更多的信息。
二、Keras实现GRU
在这里,同样使用Imdb数据集,且使用同样的方法对数据集进行处理,详细处理过程可以参考《使用Keras进行深度学习:(五)RNN和双向RNN讲解及实践》一文。

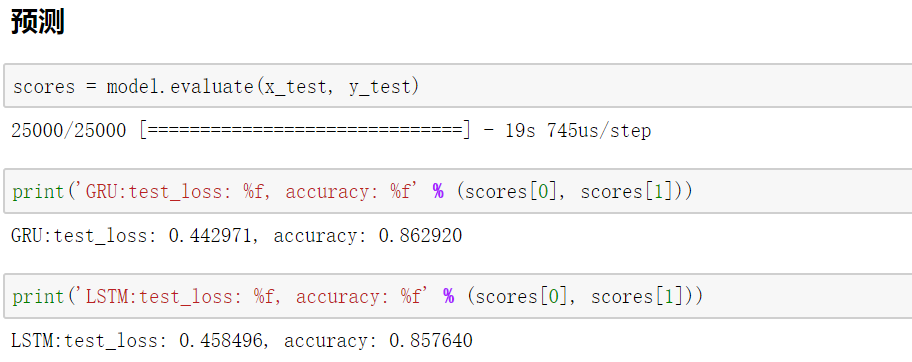
可以发现GRU和LSTM具有同样出色的结果,甚至比LSTM结果好一些。在很多时候,人们更愿意使用GRU来替换LSTM,因为GRU比LSTM少一个门,参数更少,相对容易训练且可以防止过拟合。(训练样本少的时候可以使用防止过拟合,训练样本多的时候则可以节省很多训练时间。)因此GRU是一个非常流行的LSTM变体。同时,希望通过该文能让读者对GRU有更深刻的了解。
参考文献:https://towardsdatascience.com/understanding-gru-networks-2ef37df6c9be

