建议使用PyTorch+Kivy运行脚本,环境配置详细教程 https://www.superdatascience.com/pytorch/
learning=> after a while=>
after a while=>

此无人车AI项目使用的Deep Q-learning算法,是DeepMind在2013年发明的深度强化学习算法,将Q-learning的思想与神经网络算法结合,也算是现代强化学习算法的源头了。研究者用这个算法在2015年让计算机学会了49种Atari游戏,并在大部分游戏中击败了人类。从适用性上来讲,我们不需要告诉AI具体的规则,只要让它不断摸索,它就能慢慢从中找到规律,完成许多之前被认为只有人类能完成的智力活动。
既然是Q-learning和Deep learning的结合,就先结合无人车AI来讨论什么是Q-learning。
Q-learning是一种强化学习算法,无人车需要根据当前状态来采取动作,获得相应的奖励之后,再去改进这些动作,使得下次再到相同的状态时,无人车能做出更优的选择。我们用Q(S,A)表示在S状态时,采取A动作所获得的效用值。下面用字母R代表奖励(Rewards),S’代表采取A动作后到达的新位置。(奖励值R与效用值Q的区别在于,R表示的是这个位置的奖励,比如对于无人车而言障碍物的位置奖励是-100,河流的位置奖励是-120,柏油路的奖励是100,沙路的奖励是50。而Q代表的是,采取这个动作的效用值,用于评价在特定状态下采取这个动作的优劣,可以将之理解为无人车的大脑,它是对所有已知状态的综合考虑)
伪代码如下:
[code lang=text]
Initialize Q arbitrarily // 随机初始化Q值
Repeat (for each episode): // 每一次尝试,从车子出发到撞墙是一个episode
Initialize S // 车辆出发,S为初始位置的状态
Repeat (for each step of episode):
Q(S,A) ← (1-α)*Q(S,A) + α*[R + γ*maxQ(S',a)] // Q-learning核心贝尔曼方程,更新动作效用值
S ← S' // 更新位置
until S is terminal // 位置到达终点
[/code]
贝尔曼方程(Bellman Equation)中,γ为折扣因子,α为学习速率。γ越大,无人车会越重视以前的经验,越小就更重视眼前利益。α取值范围为0~1,取值越大,保留之前训练的效果就越少。可以看出当α取值为0时,无论如何训练AI也无法学习到新Q值;α取值为1时,新Q值将完全取代旧Q值,每次训练得到新值就会完全忘记之前的训练结果。这些参数值都是人为设定的,需要根据经验慢慢调整。
然后我们将Q-learning算法与深度学习结合。从High Level来看,Q-learning已经实现无人车基本的躲避路障功能,而深度学习算法可以让无人车自动总结并学习特征,减少人为设定特征的不完备性,以更好的适应非常复杂的环境条件。
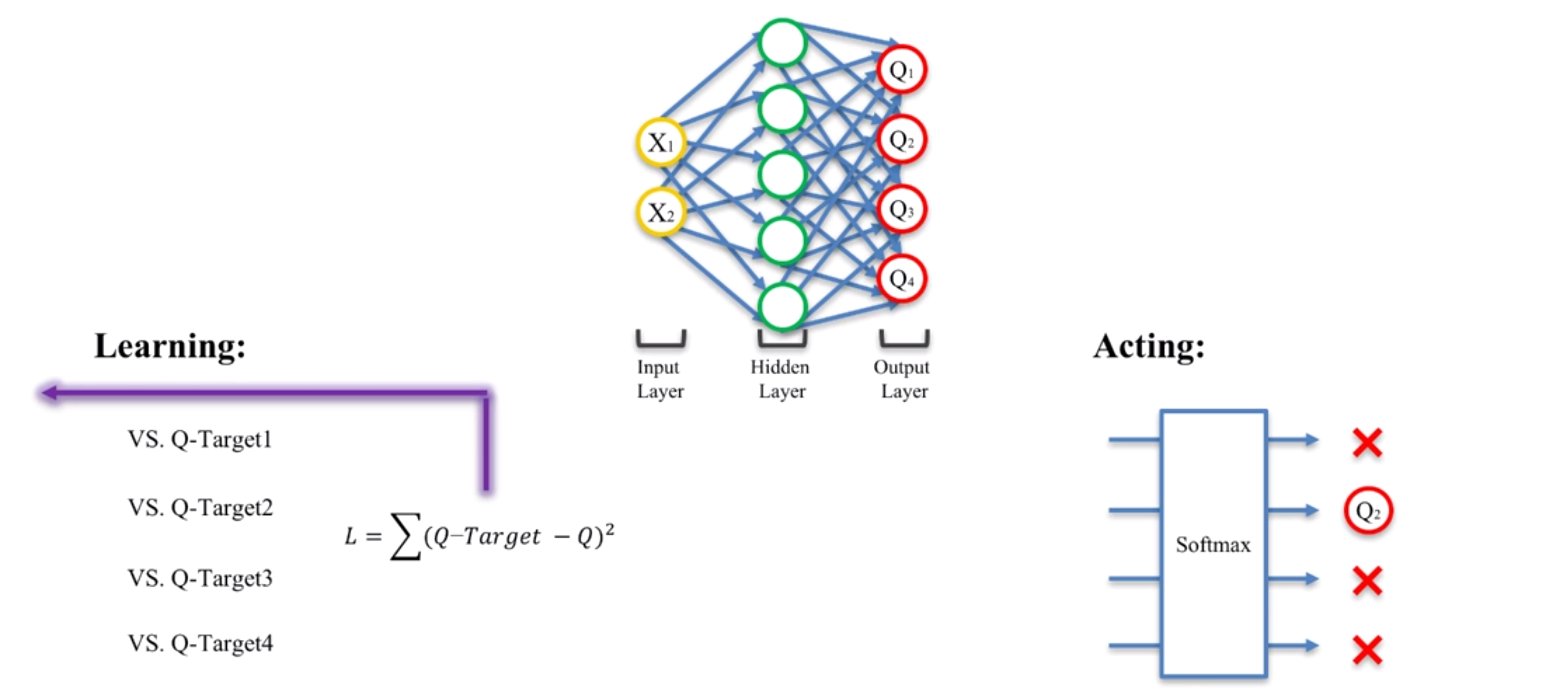
首先,用一个深度神经网络来作为Q值的网络,地图上每个点有坐标(X1, X2),将此状态输入神经网络来预测每个方向的Q值(图中假设有四个actions对应四个方向,所以一共得到4个新的Q值)。Q-target表示上一次到达该状态时所得到的Q值,然后使用均方差(mean-square error)来定义Loss Function。

计算出的L值被反馈(back-propagation)以计算每个突触(绿色圈圈)的权重w。
需要注意的是,上面的过程我们称之为”学习”(learn),尽管我们对比了以前的Q值并反馈给输入端,但是这一次计算得到的Q值是不变的。我们接下来要做的是根据这一次计算得到的Q值,做出一个”动作”(act)。

决定”动作”的过程,就是将得到的Q值传入”Softmax-Function”的过程。”Softmax-Function”是一个动作选择策略,它可以帮助我们根据当前的数据做出最优选择,原理涉及到概率论,这里就注重于应用层了,代码中有详细注释,想要深入了解可以参考Wiki。
那么为什么不直接选择最大的Q值所对应的action,而是用Softmax-Function来做决定?这里就涉及到几种动作选择策略。直接选择最大的Q值并不是不可以,这种就叫做贪心策略,缺点是很容易陷入局部最优解。因为如果执行了某个动作后,最终达到了目标,那么这种策略就会在后续此状态时一直选择这种动作,导致没有机会探索全局最优解。
项目地址:https://github.com/JianyangZhang/Self-Driving-Car-AI

